
Overview
Analytics provides a history of all administrative tasks through two views: the Dashboard view and the Data view. Switch between them using the toggle at the top right of the Analytics page. The views display key performance metrics, trends, and reports, enabling you to gauge real-time usage and performance.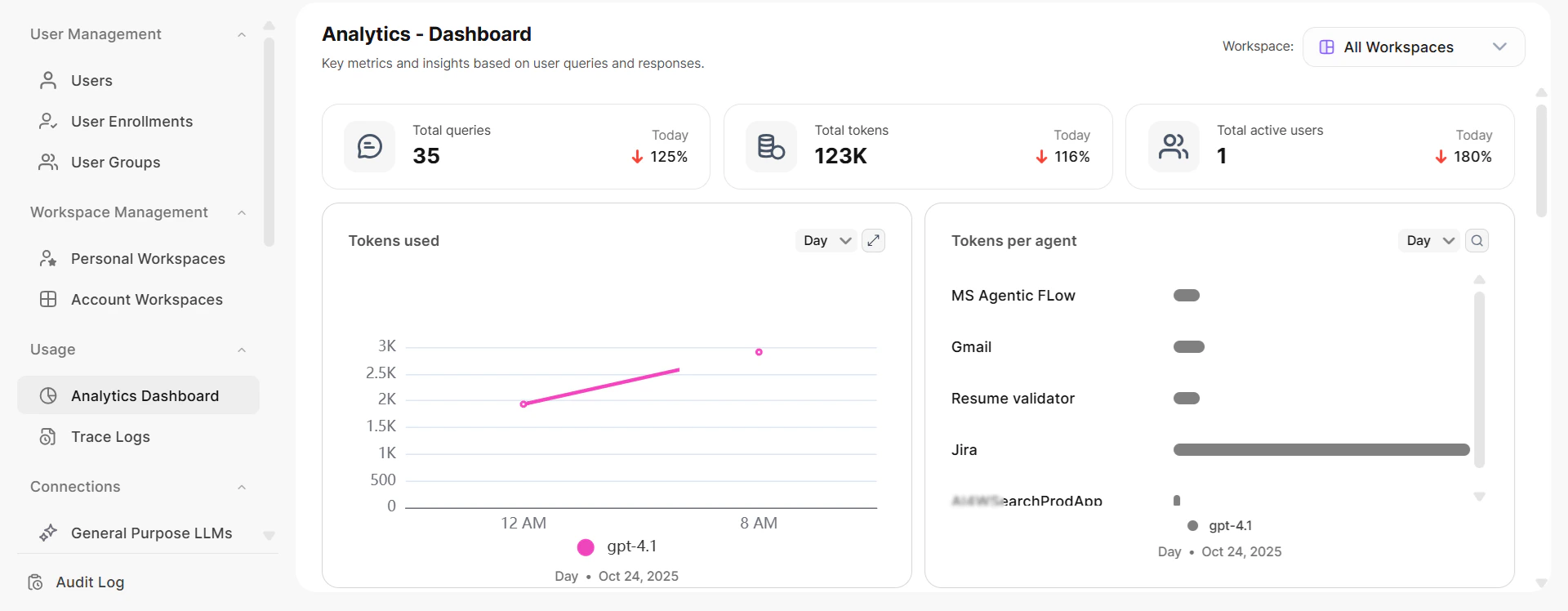
Dashboard View
The Dashboard view provides graphical reports on usage, performance, and feedback. At the top, you can see the total queries, total tokens, and total active users for the day.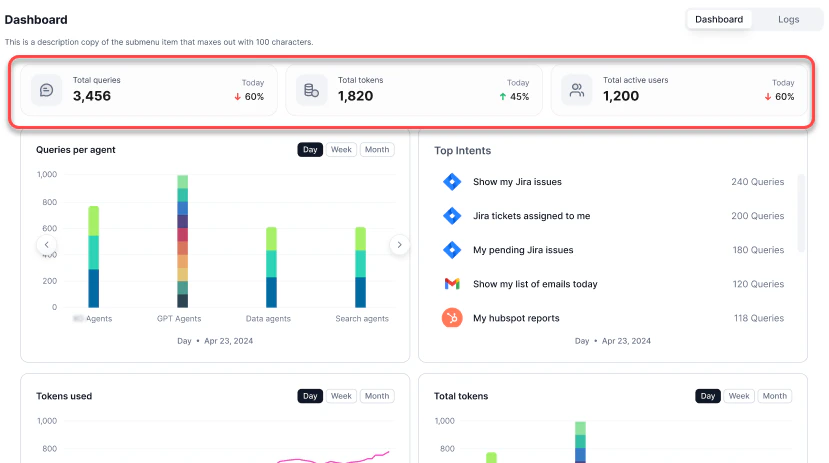
| Report | Description |
|---|---|
| Tokens Used | Token usage trends across models |
| Tokens Per Agent | Token consumption broken down by agent |
| Queries Per Agent | Query volume per agent by type |
| Top Agents | Agents ranked by query volume |
| Top Users | Top 10 users by query count |
| Users | Unique users by platform (web vs. native) |
| Average Response Time | Average response time of the service |
| Errors | Queries with errors over time |
| Feedback | End-user feedback on responses |
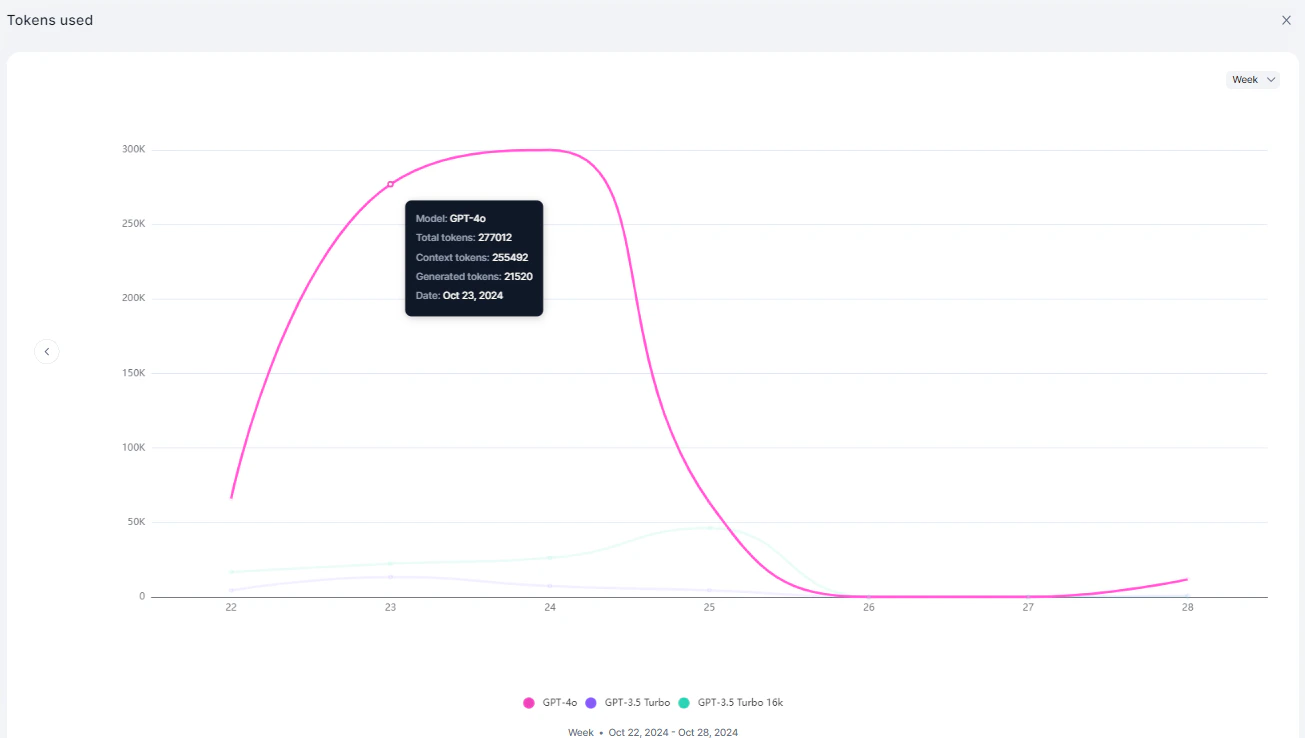
Tokens Used
Displays token usage trends across models.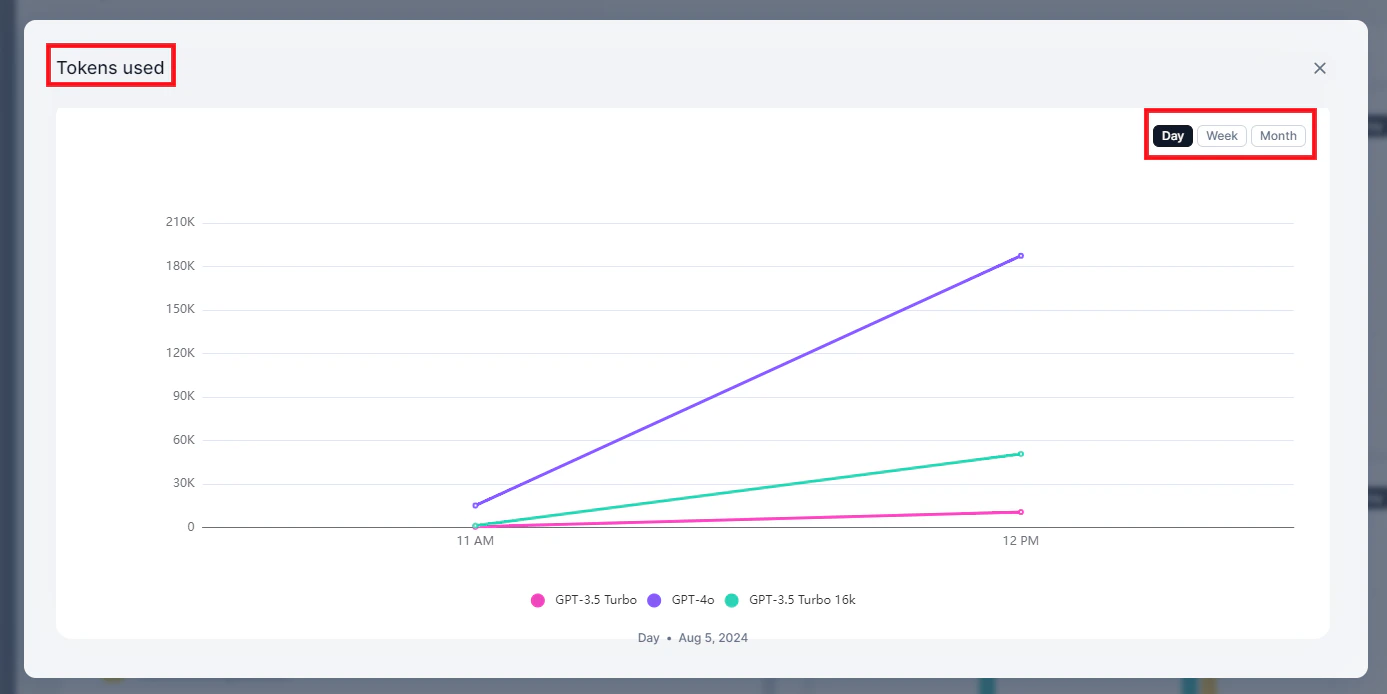
| Metric | Description |
|---|---|
| Model Name | The LLM model used |
| Total Tokens Used | Combined context and generation tokens |
| Context Tokens | Tokens in the input/context |
| Generation Tokens | Tokens in the response |
| Timestamp | Date and time of usage |
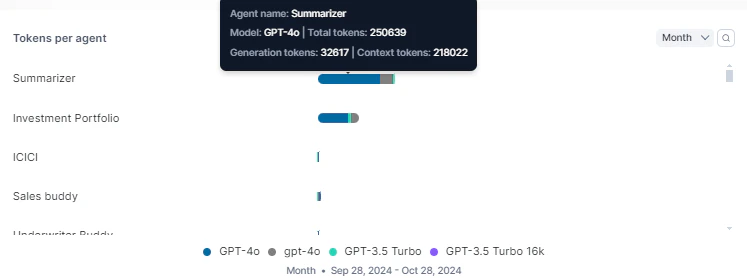
Tokens Per Agent
Displays token consumption broken down by agent.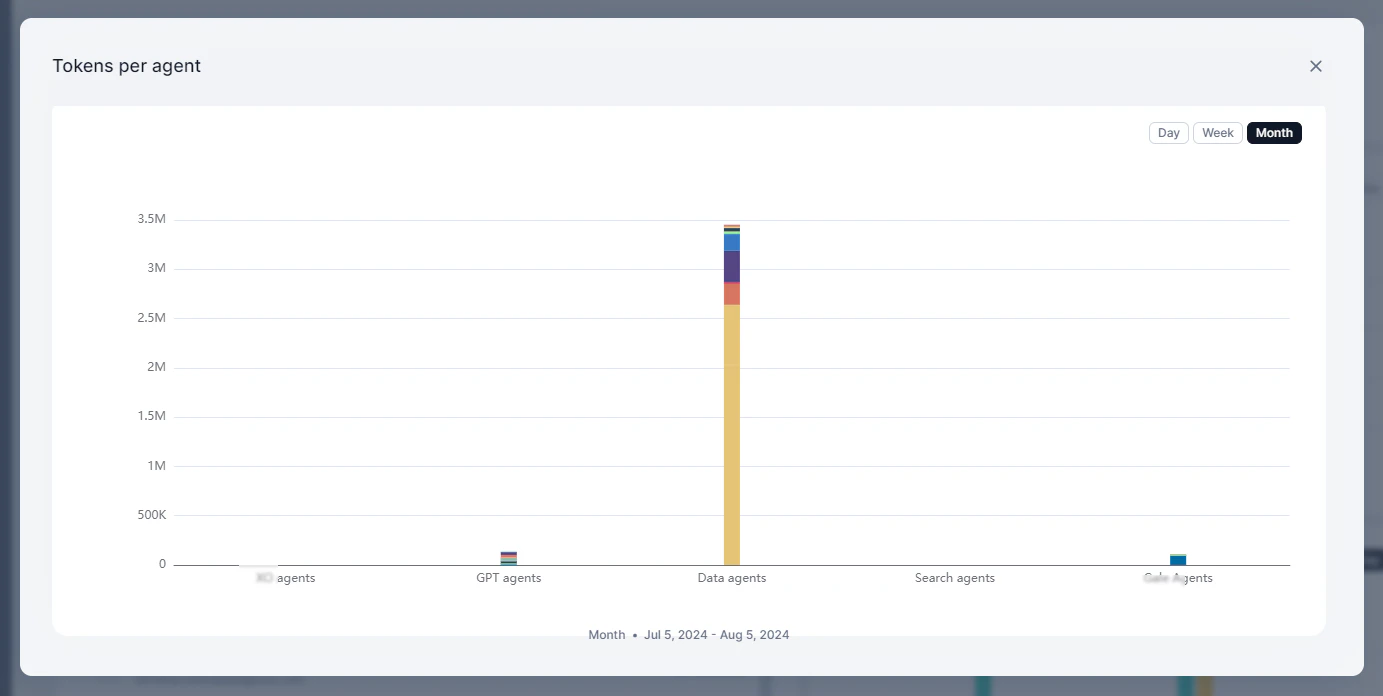
| Metric | Description |
|---|---|
| Agent Name | Name of the agent |
| Model Name | LLM model used by the agent |
| Total Token Count | Combined context and generation tokens |
| Generation Token Count | Tokens in the response |
| Context Token Count | Tokens in the input/context |
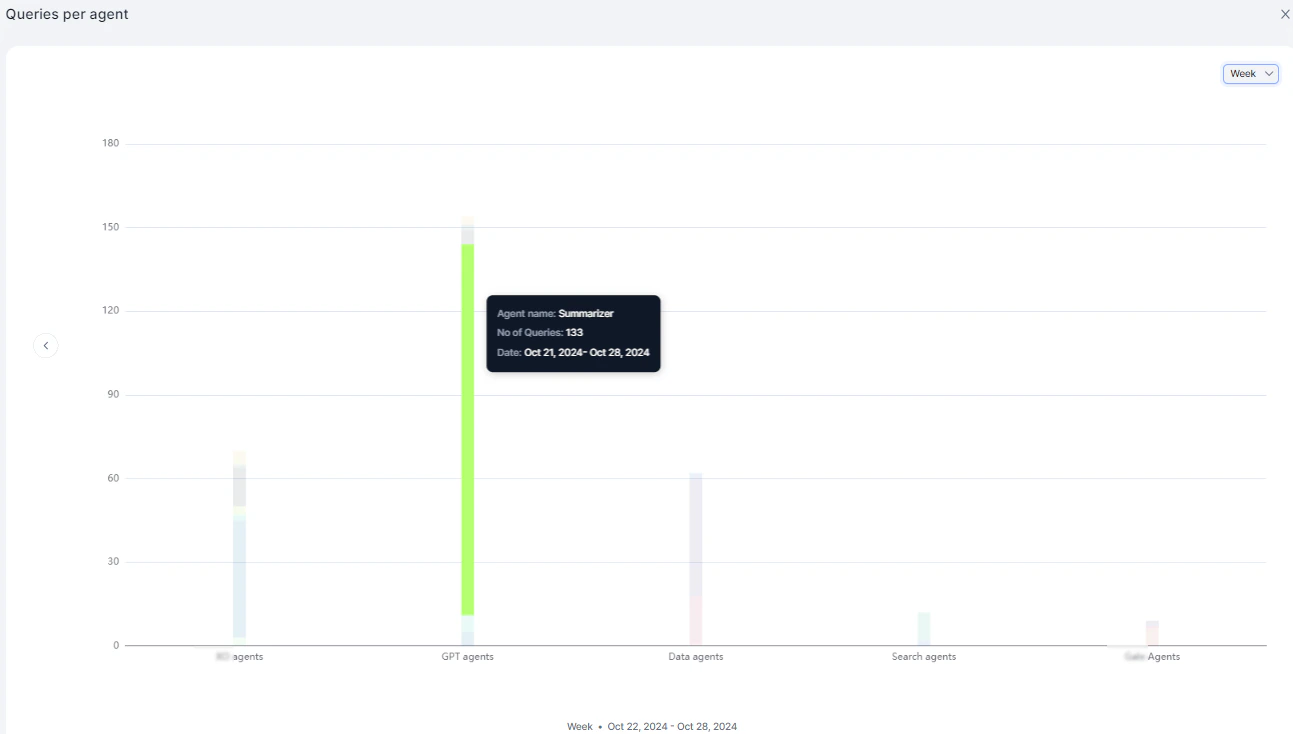
Queries Per Agent
Displays query volume by agent, categorized by agent type: AI for Service, GPT, Data, Search, and Workflow.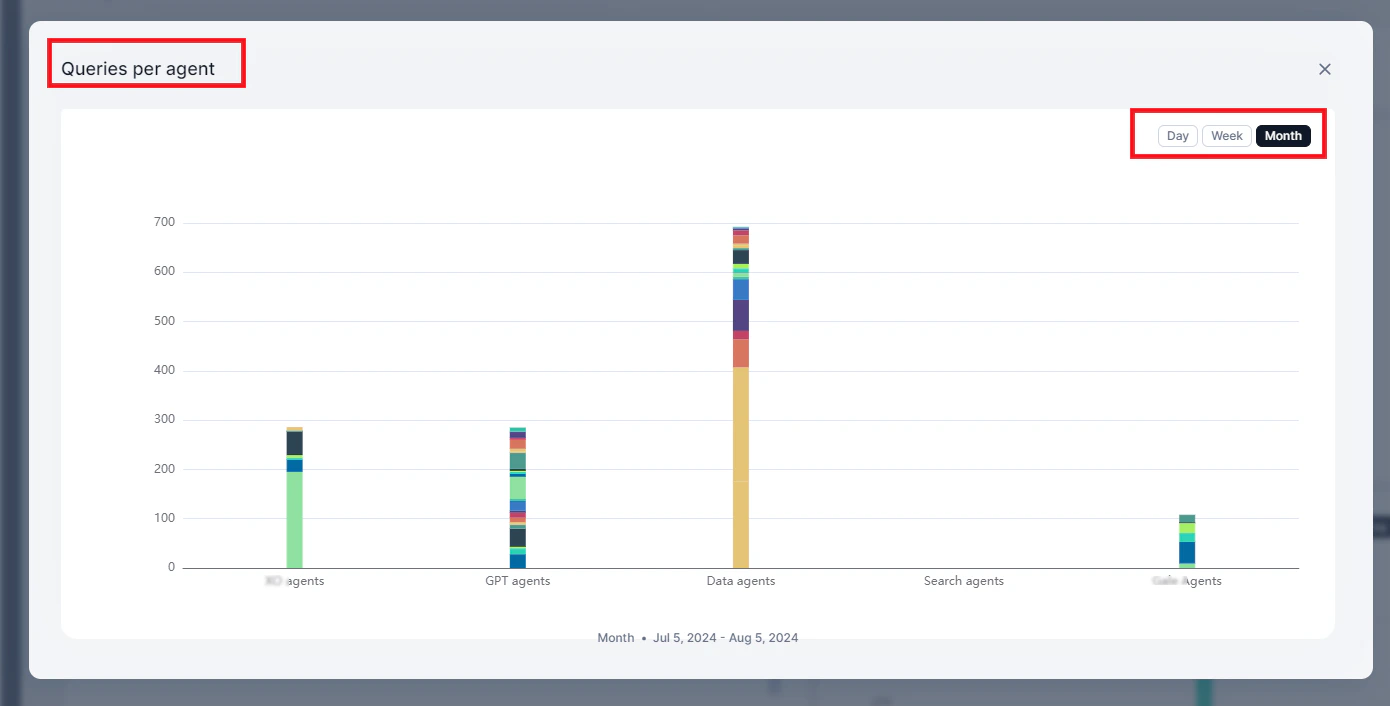
| Metric | Description |
|---|---|
| Agent Name | Name of the agent |
| No. of Queries | Total queries handled |
| Timestamp | Date and time |
Top Agents
Displays agents ranked by query volume in descending order.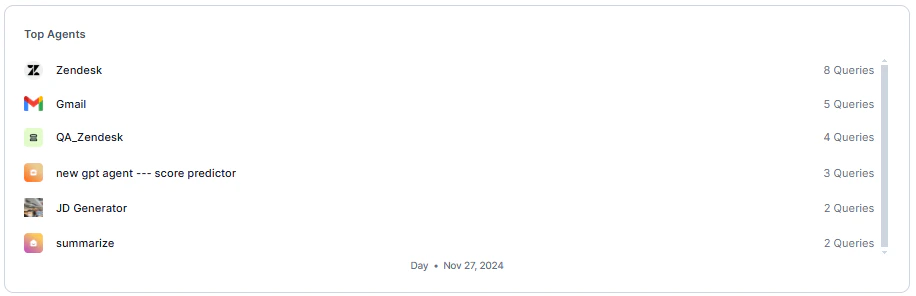
Top Users
Displays the top 10 users by query count.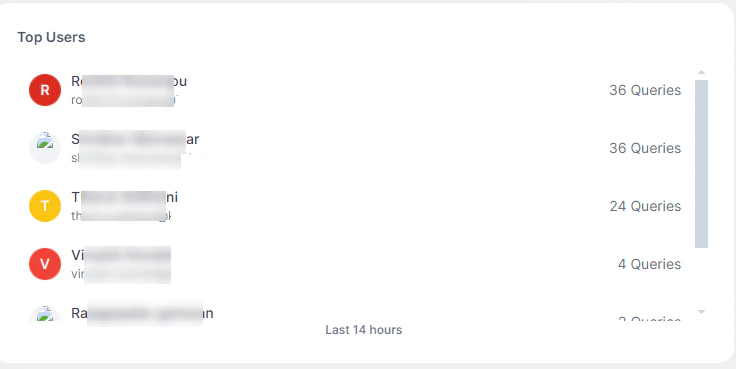
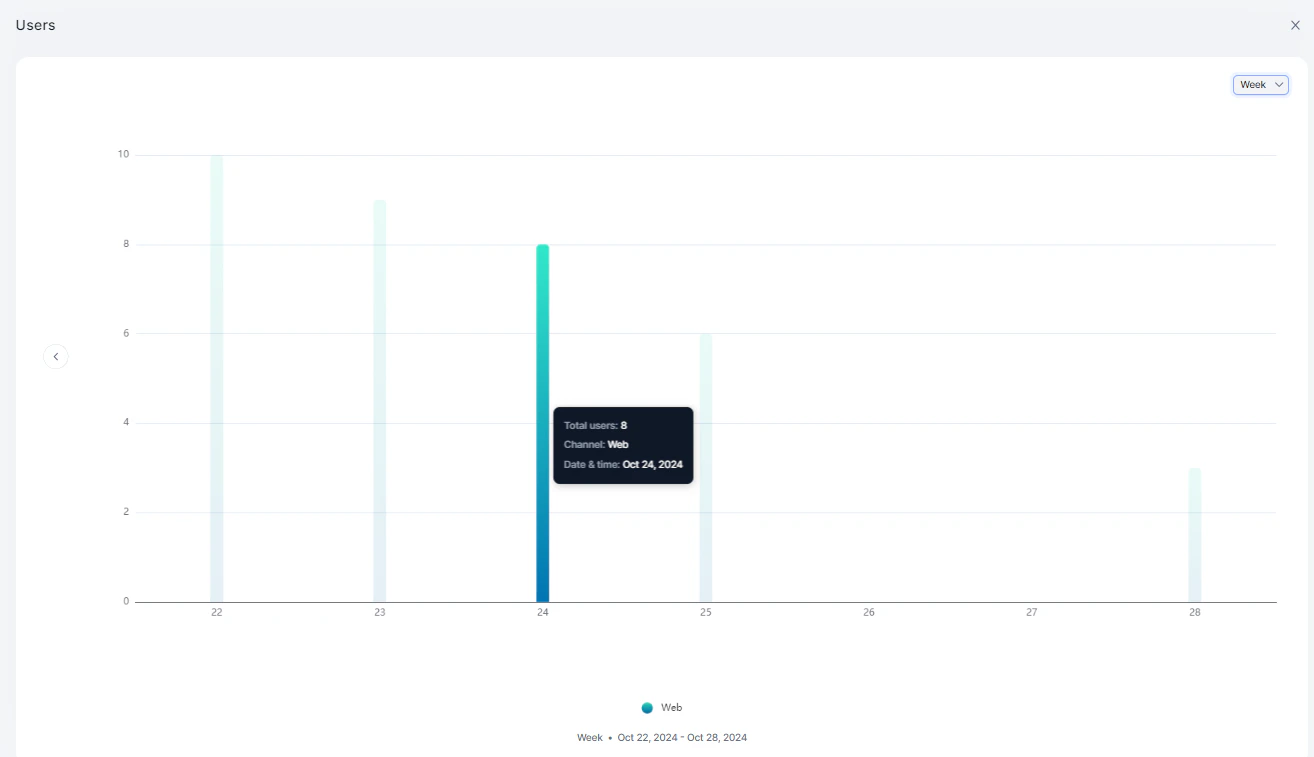
Users
Displays unique users interacting with the system, comparing web vs. native platforms.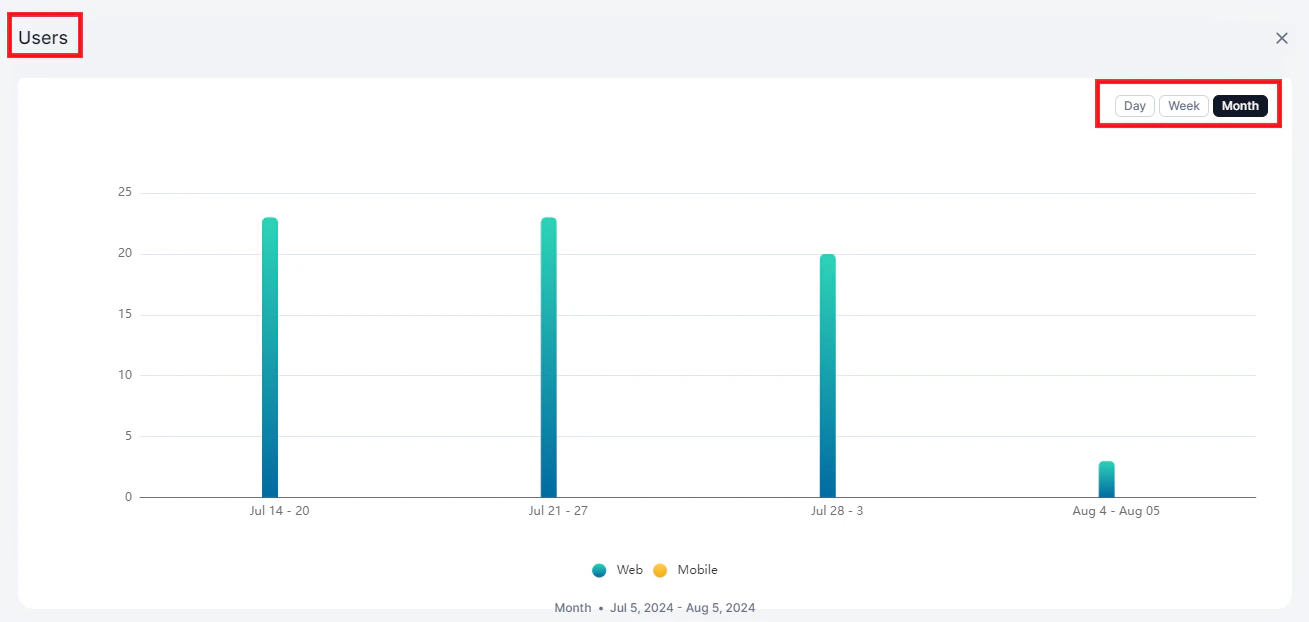
| Metric | Description |
|---|---|
| Total Users | Unique user count |
| Channel | Web or native platform |
| Timestamp | Date and time |
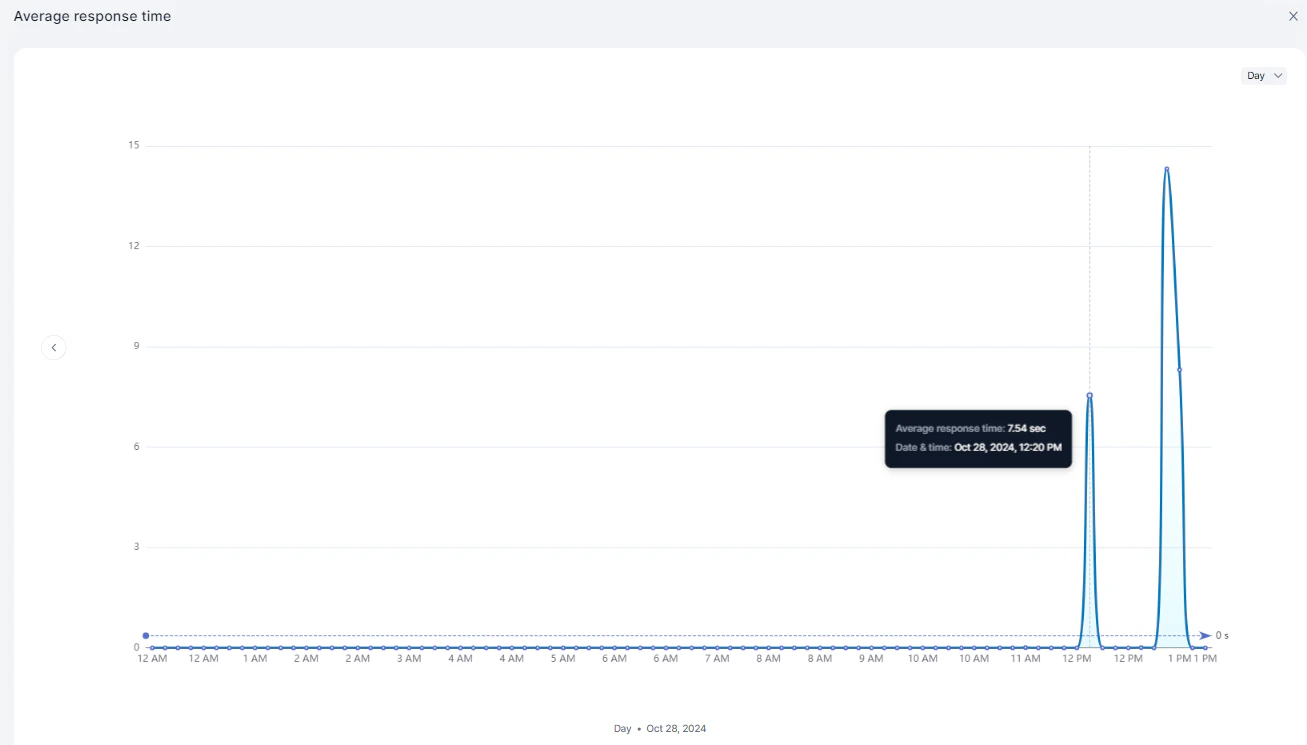
Average Response Time
Displays the average response time of the service over time.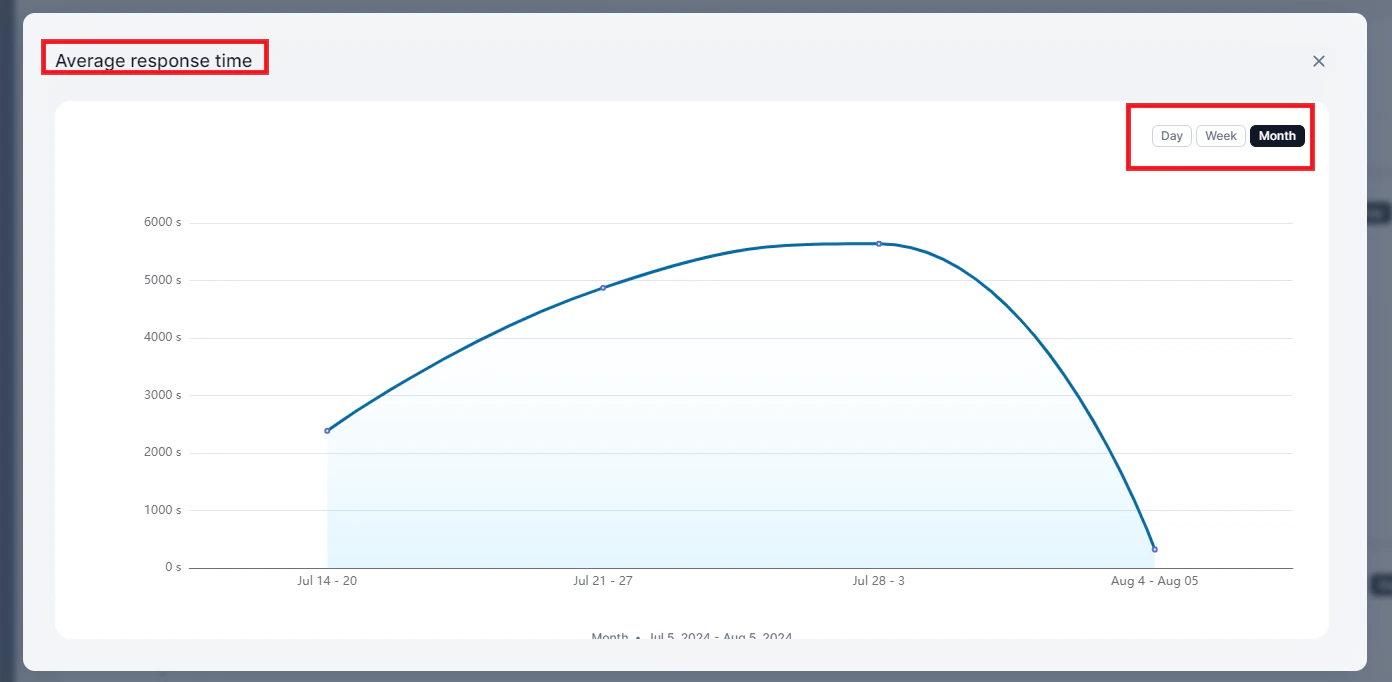
| Metric | Description |
|---|---|
| Average Response Time | Mean response time per period |
| Timestamp | Date and time |
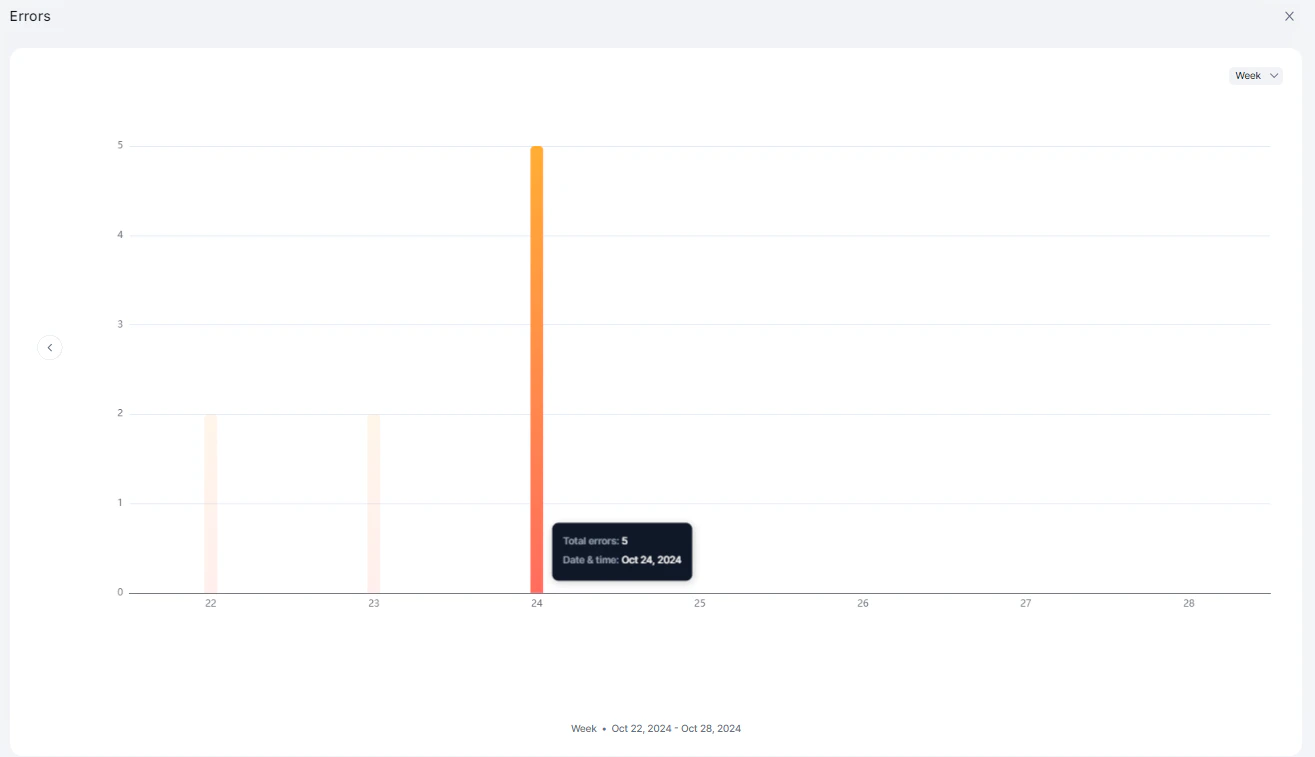
Errors
Displays the number of queries that resulted in errors over time.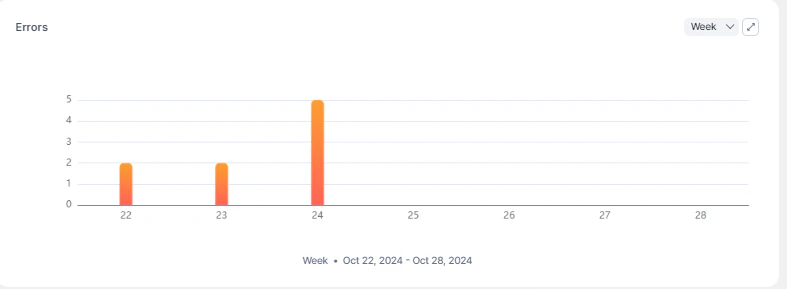
| Metric | Description |
|---|---|
| Total Errors | Count of error responses |
| Timestamp | Date and time |
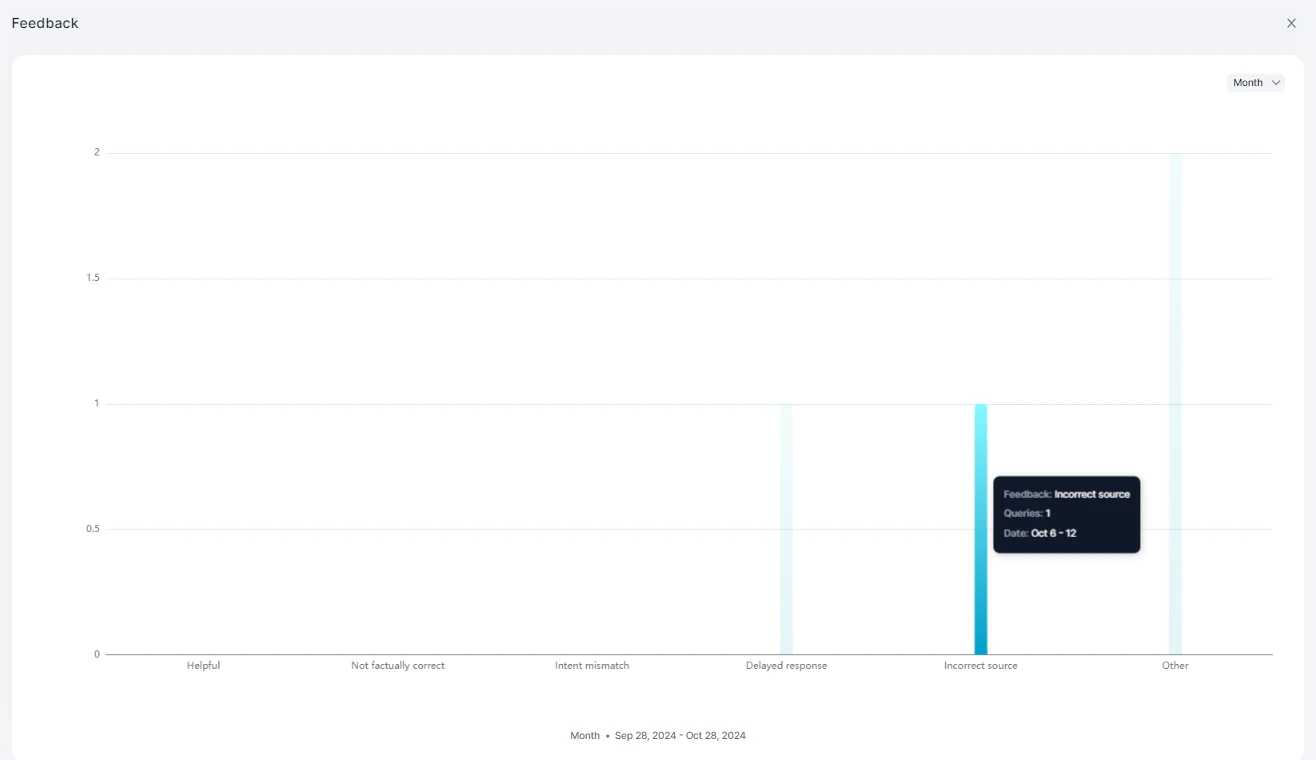
Feedback
Displays end-user feedback on responses.
| Metric | Description |
|---|---|
| Feedback | Feedback type (positive/negative) |
| Queries | Associated query count |
| Timestamp | Date and time |
Data View
The Data view lists individual query records. Each record corresponds to a user utterance.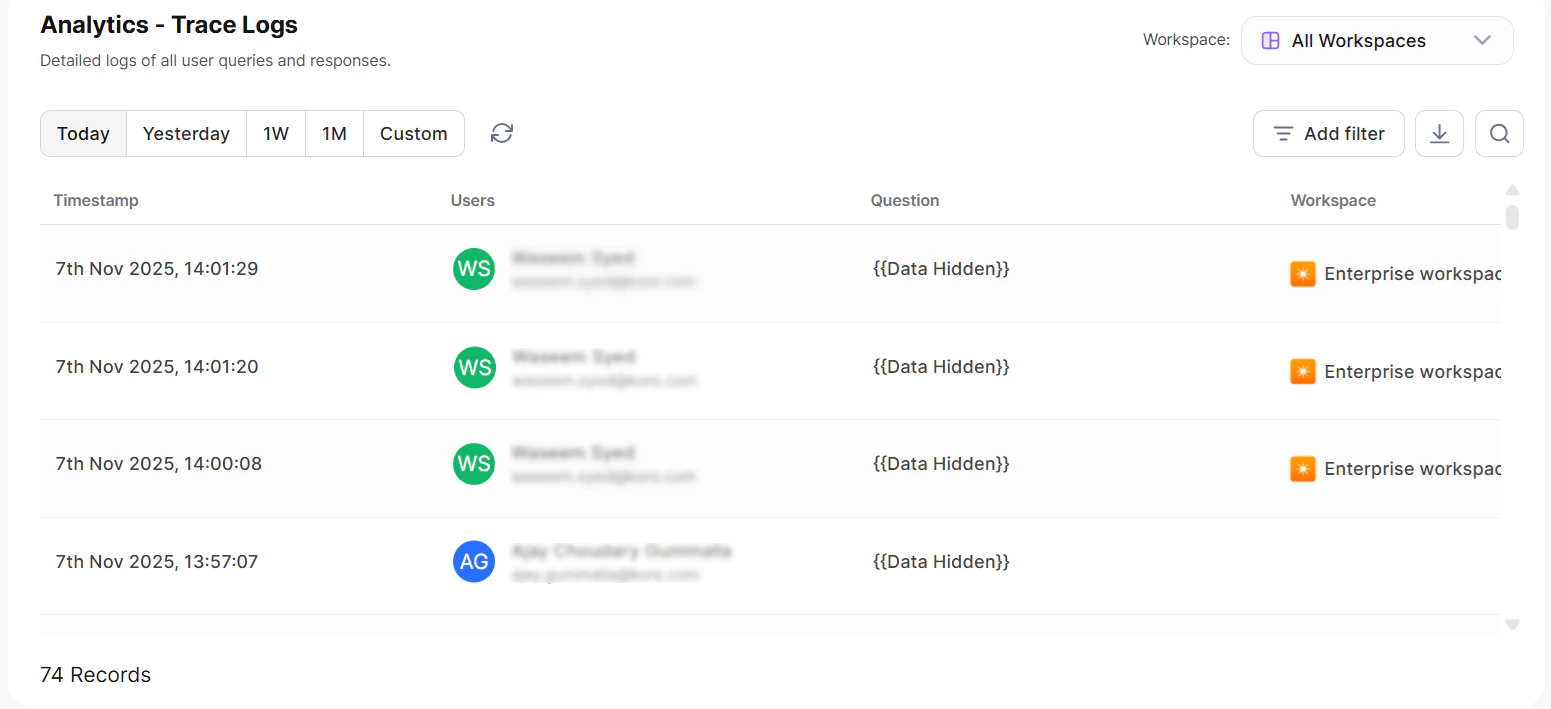
| Column | Description |
|---|---|
| Request ID | Unique identifier for the request |
| Users | User who submitted the query |
| Questions | The user utterance |
| Overall Tokens | Total tokens consumed |
| Response Time | Time taken to respond |
| Agent Type | Type of agent that handled the query |
| Status | Response status |
| Timestamp | Date and time of the request |
Record Details
Request Information| Field | Description |
|---|---|
| Request ID | Unique identifier |
| User Name and Email | Identity of the user |
| User ID | System user identifier |
| Channel | Mobile or Web |
| Previous Context | Whether prior context was used (Yes/No) |
| Thread ID | Conversation thread identifier |
| Feedback Comments | User-submitted feedback |
| Timestamp | Date and time |
| Field | Description |
|---|---|
| Question | The user utterance |
| Query Points | Key points extracted from the query |
| Field | Description |
|---|---|
| Model | LLM model used |
| Total Tokens | Combined token count |
| Request Tokens | Context/input tokens |
| Response Tokens | Generation tokens |
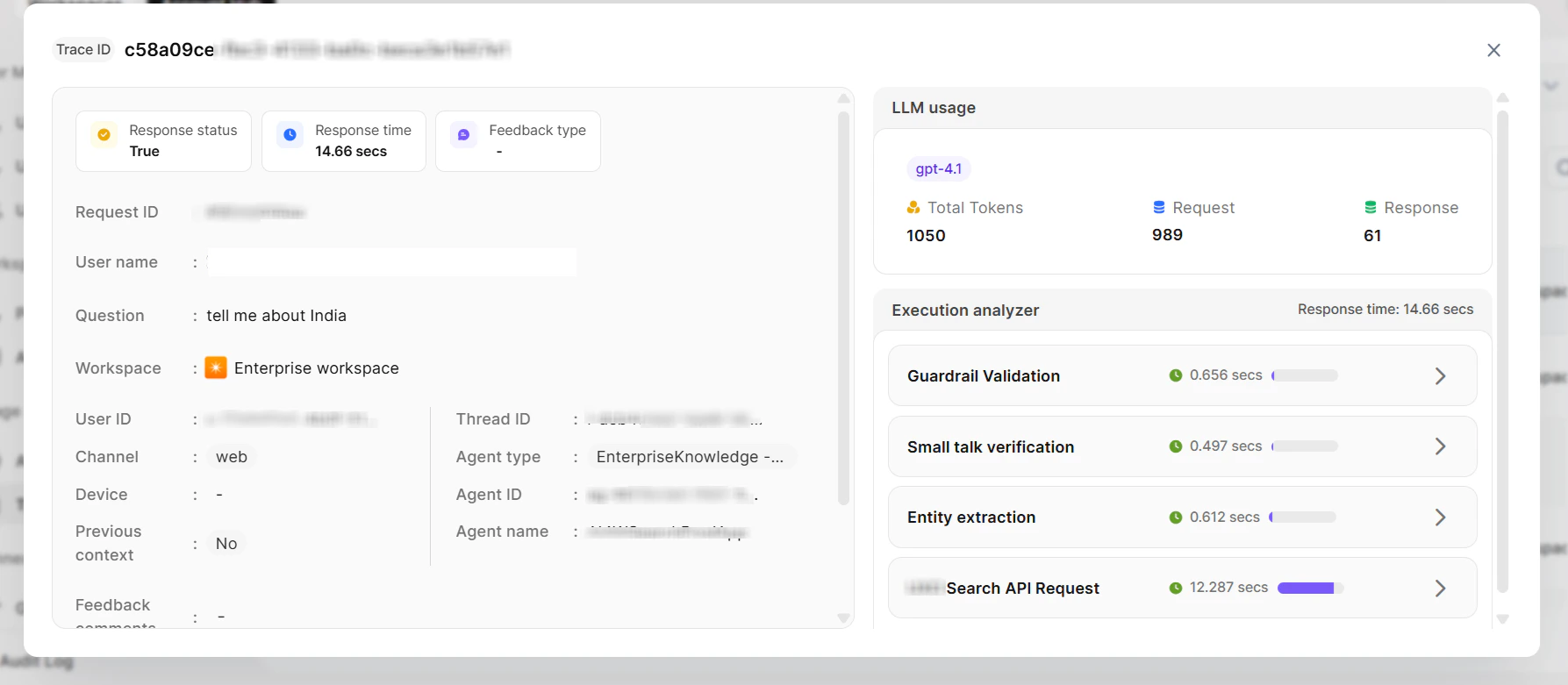
- View the exact prompt sent to the model
- Review the model’s response
- Debug individual steps to identify issues